魔窟AI助手深度解析:AI编程助手底层原理与面试考点全攻略
发布时间:北京时间 2026年4月9日
目标读者:技术入门/进阶学习者、在校学生、面试备考者、相关技术栈开发工程师
文章定位:技术科普 + 原理讲解 + 代码示例 + 面试要点,兼顾易懂性与实用性
一、引言:AI编程助手为何成为开发者“标配”?
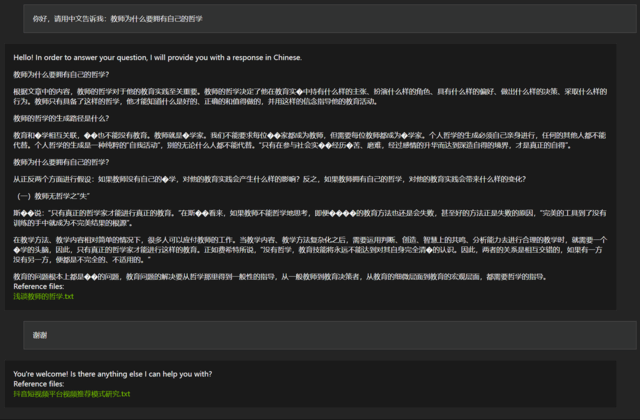
2026年,AI编程助手已不再是可选项,而是现代软件开发的核心基础设施。从2025年到2026年,全球AI编程工具市场从294.7亿美元增长至345.8亿美元,年复合增长率高达17.52%-。更值得关注的是,高达90%的专业开发者已在日常工作中使用AI编程工具-60。
许多开发者仍然面临相同的困境:会用、不懂原理,面试一问就卡壳。你打开编辑器,AI帮你补全了代码,但你真的知道它为什么能猜到你的意图吗?你知道它背后的Transformer是怎么理解你写的函数吗?面对面试官“请解释LLM如何生成代码”的问题,你只能答“模型很大,数据很多”吗?
这就是本文要解决的问题。我们将系统梳理AI编程助手的核心概念、技术原理、工程实现和高频面试考点,助你建立从概念到原理的完整知识链路。
二、痛点切入:传统开发模式为何“撑不住”了?
让我们先看一段传统开发中常见的代码:
传统方式:手动编写工具函数 def calculate_discount(price, discount_rate): discounted_price = price (1 - discount_rate) return round(discounted_price, 2)
这个函数看起来没问题,但当需求变成“支持多种折扣类型、自动生成单元测试、添加日志和异常处理”时,问题就来了:
代码冗余:每个工具函数都要手动编写重复的模板代码
维护困难:逻辑分散在多个文件中,修改一处可能需要改几十处
效率瓶颈:开发者把大量时间花在“写代码”而非“设计代码”上
质量参差:不同开发者写的代码风格、健壮性差异巨大
一项面向数千名开发者的调查显示,66%的开发者最常遇到的AI编程问题是“AI生成的答案接近正确但总差一点”,另有45.2%的开发者表示调试AI生成的代码比手动写代码更耗时-64。这揭示了一个核心矛盾:AI编程助手虽然能大幅提升代码产出,但理解AI如何工作才是高效使用的关键。
正是为了解决这些痛点,基于大语言模型的AI编程助手应运而生。
三、核心概念讲解:大语言模型(LLM)
定义
大语言模型(Large Language Model,LLM) 是一种在包含海量文本数据(包括大量编程代码)上训练的深度神经网络,其核心任务是预测序列中的下一个Token-。
关键词拆解
| 关键词 | 内涵 |
|---|---|
| “大” | 参数量通常在数十亿到数万亿之间,如GPT系列模型 |
| “语言” | 训练数据以自然语言和编程语言为主 |
| “模型” | 本质是统计模型,学习的是数据中的模式 |
生活化类比
想象一下,LLM就像一个阅读了全世界所有编程书籍、GitHub仓库和Stack Overflow问答的“超级学霸”。当你给它一个问题时,它不会去“思考”逻辑推导,而是回忆它在海量数据中见过的类似模式,然后给出最可能正确的延续——就像一个熟读唐诗三百首的人,看到“床前明月光”会自然接上“疑是地上霜”。
核心作用
LLM为AI编程助手提供了语义理解和代码生成两大基础能力,是整条技术链路的起点。
四、关联概念讲解:智能体(Agent)
定义
AI编程智能体(Agent) 是多个LLM协作的程序包装器,能够理解任务、规划步骤、调用工具、执行命令并在遇到错误时自主恢复-34-16。
与LLM的关系:LLM是“大脑”,Agent是“身体”
LLM:负责理解用户意图、生成代码内容——相当于“思考”部分
Agent:负责任务拆解、工具调用、文件操作、错误恢复——相当于“行动”部分
核心差异对比
| 维度 | LLM(基础模型) | Agent(智能体) |
|---|---|---|
| 能力边界 | 单轮文本生成 | 多步骤任务规划与执行 |
| 工具使用 | 不支持(纯文本) | 可调用grep、文件读写、执行命令等 |
| 状态管理 | 无 | 维护任务状态和多轮上下文 |
| 典型代表 | GPT-4、Claude | Claude Code、Cursor Composer |
运行机制示例
Anthropic的工程文档将Agent的工作模式概括为:收集上下文 → 采取行动 → 验证工作 → 重复-34。这个循环不断迭代,直到任务完成。
五、概念关系与区别总结
一句话记忆:LLM是AI编程助手的“大脑”(负责想),Agent是“手和脚”(负责做) 。
更精确地说:
LLM提供的是推理和生成能力
Agent提供的是规划和执行能力
AI编程助手 = LLM + Agent + 上下文工程 + IDE集成
记忆口诀:LLM想方案,Agent去执行,两者结合才成“编程助手”。
六、代码示例:极简AI编程助手实现
下面的示例展示了如何用一个LLM调用实现最简单的代码生成功能:
极简AI编程助手实现(伪代码示意) import openai def ai_code_assistant(user_prompt, context): """ 核心原理:将用户需求 + 代码上下文 → LLM → 生成代码 """ Step 1: 构造完整提示词 full_prompt = f""" 你是一个编程助手。根据以下需求生成代码。 代码上下文(当前文件的部分内容): {context} 用户需求: {user_prompt} 请直接输出代码,不要额外解释: """ Step 2: 调用LLM(核心生成步骤) response = openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "user", "content": full_prompt}], temperature=0.3 低温度 → 更确定性输出 ) Step 3: 提取并返回生成的代码 generated_code = response.choices[0].message.content return generated_code 使用示例 context_code = """ def calculate_discount(price, discount_rate): return price (1 - discount_rate) """ result = ai_code_assistant("给这个函数添加类型注解和文档字符串", context_code) print(result)
关键步骤标注
| 步骤 | 作用 | 技术要点 |
|---|---|---|
| ① 构造提示词 | 将用户意图转化为模型可理解的输入 | 包含角色设定、任务描述、输出格式约束 |
| ② 调用LLM | 核心生成过程 | 基于Transformer自注意力机制 |
| ③ 后处理 | 提取有效代码 | 需处理模型可能输出的额外说明文字 |
新旧方式对比
| 维度 | 传统开发 | AI编程助手 |
|---|---|---|
| 写工具函数 | 逐行手动编写 | 自然语言描述 → 自动生成 |
| 写单元测试 | 手动写几十行 | “为这个函数生成测试” |
| 调试错误 | 手动排查 | AI分析错误并给出修复建议 |
七、底层原理:Transformer与代码生成的奥秘
核心基础——Transformer自注意力机制
AI编程助手的代码生成能力根植于Transformer架构,其核心是自注意力机制(Self-Attention)。在代码场景中,自注意力机制能捕捉变量、函数、类之间的依赖关系——例如,处理一段Python代码时,模型能分析price与discounted_price之间的数值传递关系、discount_rate对计算结果的影响路径-35。
从自然语言到可执行代码:三层映射
当用户输入“实现一个支持分页查询的Spring Boot接口”时,现代AI编程模型会在三个层次上进行处理-32:
| 层次 | 处理内容 | 示例 |
|---|---|---|
| 语法层 | 识别关键词对应的代码结构 | 识别“Spring Boot”“分页查询”→Pageable参数 |
| 业务层 | 推断业务逻辑和默认值 | page=0, size=10, 异常处理 |
| 工程层 | 自动补全工程实践 | @RestController注解、DTO转换 |
底层技术支撑体系
AI编程助手的完整技术栈包含多个层级:
模型层:Transformer架构 + 自注意力机制 + 位置编码
训练层:预训练(数十亿行代码)→ 微调(SFT)→ 对齐(RLHF)
工程层:RAG检索增强生成 + 上下文工程 + 工具调用(Tool Calling)
硬件层:NVIDIA Blackwell等GPU加速推理(如Cursor的Warp Decode技术将MoE模型推理速度提升1.84倍)-25
重点提示:面试时,能清晰地讲出“Transformer → 自注意力 → 代码语义理解”这条链路,会大幅提升面试官对你的评价。
八、高频面试题与参考答案
面试题1:LLM生成代码的技术原理是什么?
参考答案要点:
① Transformer架构:基于自注意力机制,能捕捉代码中变量、函数之间的长距离依赖关系。
② 训练流程:预训练(海量代码数据)→ 有监督微调(SFT)→ RLHF(人类反馈强化学习)。
③ 生成机制:自回归方式逐Token生成,每次根据已有Token预测下一个,直到完成整个代码块-。
④ 上下文理解:通过位置编码保持代码的顺序信息,通过注意力权重关注相关的代码片段-35。
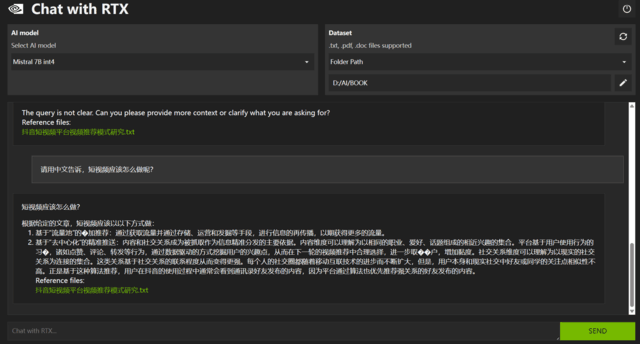
面试题2:什么是RAG?为什么AI编程助手需要RAG?
参考答案要点:
① 定义:RAG(Retrieval-Augmented Generation,检索增强生成)= 检索 + 生成。将外部知识库转为向量并存入数据库,用户提问时检索相关内容拼接进Prompt-71。
② 必要性:LLM的训练数据有截止日期,无法了解项目私有的代码库、API文档和业务逻辑。RAG让AI能在生成时动态获取项目相关信息。
③ 在编程场景的应用:当AI需要理解项目中未公开的代码或文档时,通过RAG检索相关片段,避免“幻觉”问题。
面试题3:LLM和Agent有什么区别?
参考答案要点:
① 定义差异:LLM是基础语言模型,核心任务是预测下一个Token;Agent是多个LLM协作的程序包装器,能规划和执行多步骤任务-34。
② 能力边界:LLM只能做单轮文本生成;Agent可以拆解任务、调用工具、修改文件、从错误中恢复-16。
③ 典型例子:GPT-4是LLM,Claude Code是Agent——前者只生成文本,后者可以 grep 代码、修改文件、运行测试。
面试题4:如何设计一个高质量的Prompt来生成可靠的代码?
参考答案要点:
① 角色设定:明确AI的身份(如“你是一名资深Python工程师”)。
② 任务分解:将复杂需求拆分为多个子任务。
③ 输出格式约束:指定输出格式(如“只输出代码,不要解释”)-71。
④ Few-shot示例:提供1-3个输入输出的示例,引导模型学习预期模式-71。
⑤ 约束规则:增加限制条件(如“使用Python 3.9+语法”“不依赖第三方库”)。
九、结尾总结
核心知识点回顾
LLM是基础:Transformer架构 + 自注意力机制,是AI编程助手的“大脑”。
Agent是执行层:规划、调用工具、多轮迭代,让AI从“会想”到“会做”。
RAG增强上下文:让AI能“看懂”你的私有代码库,而不是依赖过时的训练数据。
从Prompt到Context:提示工程正在进阶为上下文工程,理解上下文管理是高效使用AI编程助手的关键-43。
重点与易错点
✅ 重点:Transformer自注意力机制 → LLM生成原理 → Agent多步执行 → RAG增强
❌ 易错:把Agent和LLM混为一谈、忽视RAG在私有代码库中的作用、忘记Prompt工程中的格式约束
进阶预告
下一篇文章,我们将深入AI编程助手的工程落地实践,包括:
如何在企业内部安全合规地部署AI编程工具
多Agent协作的架构设计与实现
AI生成代码的安全审查最佳实践
如果您对文中某个技术点有疑问,或希望补充某个方向的内容,欢迎留言交流!
相关文章
最新评论