AI文助手深度拆解:技术原理与面试备战全攻略(2026年4月9日)
一、基础信息配置
文章标题(长度29字):
AI文助手深度拆解:技术原理与面试备战全攻略(2026年4月9日)
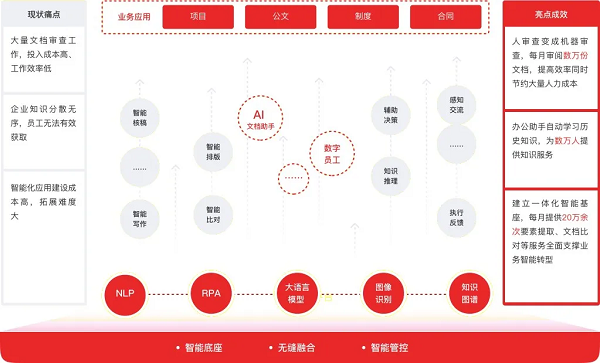
目标读者:技术入门 / 进阶学习者、在校学生、面试备考者、相关技术栈开发工程师
文章定位:技术科普 + 原理讲解 + 代码示例 + 面试要点,兼顾易懂性与实用性
写作风格:条理清晰、由浅入深、语言通俗、重点突出,少晦涩理论,多对比与示例
核心目标:让读者理解概念、理清逻辑、看懂示例、记住考点,建立完整知识链路
二、文章正文
开篇引入
在2026年的今天,“AI文助手”(AI Coding Assistant,即人工智能编程助手)已经从概念走入每一位开发者的日常。无论是GitHub Copilot自动补全代码,还是Cursor帮你重构整个模块,抑或是通义灵码在Spring Boot中精准生成业务逻辑——AI文助手正在深刻改变软件开发的实践方式。许多学习者的现状是:每天都在用AI写代码,却说不清它背后的工作原理;面试官问起“AI对后端开发的影响”,只会简单回答“提高效率”。本文将从痛点切入,拆解AI文助手的核心概念与技术原理,辅以代码示例与面试要点,帮你建立从“会用”到“懂原理”的完整知识链路。
一、痛点切入:为什么需要AI文助手?
在没有AI文助手的传统开发流程中,实现一个简单的功能往往需要经历繁琐的步骤:
传统方式:实现一个用户注册API Step 1: 手写接口定义 Step 2: 手动编写参数校验逻辑 Step 3: 重复编写CRUD代码 Step 4: 写单元测试 Step 5: 查阅文档调试
传统实现的缺点显而易见:
高耦合与代码冗余:相似的CRUD逻辑需要在不同模块反复手写
效率瓶颈:开发者花费大量时间在重复性编码上,而非解决核心业务问题
知识获取成本高:遇到新技术或框架时,需要在文档、论坛间频繁切换
据IDC数据,中国AI编程助手对开发者的覆盖率仅为30%,而美国已达91%,差距背后是巨大的效率提升空间-39。正是在这样的背景下,AI文助手应运而生——它不再是简单的代码补全工具,而是一个能够理解意图、规划任务、执行编码的智能协作者。
二、核心概念讲解:大语言模型(LLM)
定义:大语言模型(Large Language Model, LLM)是基于海量文本数据训练的大规模神经网络模型,能够理解、生成和处理自然语言。
通俗来说,LLM就像一位读过互联网上几乎所有代码和文档的“全能程序员” ——它背下了海量的编程范式、框架用法和设计模式。当开发者写下注释或输入自然语言需求时,LLM能根据上下文预测“接下来最可能出现的代码是什么”。
以OpenAI的GPT系列模型为例,其核心技术架构基于Transformer,通过多层注意力机制捕捉代码中的长距离依赖关系。GitHub Copilot的核心正是基于OpenAI的GPT模型,经过专门的代码训练和优化——训练数据来自GitHub上的海量开源代码,覆盖多种编程语言和框架-21。
作用与价值:LLM是AI文助手的“大脑”,负责理解开发者意图、生成代码建议、回答问题。它让计算机首次具备了“读懂”自然语言编程需求的能力。
三、关联概念讲解:智能体(Agent)
定义:智能体(Agent)是在LLM基础上构建的自主系统,能够进行规划、行动、观察与迭代优化,模拟人类程序员“分析需求→编写代码→运行测试→修复错误”的完整工作流-11。
如果说LLM是“大脑”,那么Agent就是拥有这个大脑的“完整程序员” 。两者最核心的区别在于:
| 对比维度 | LLM | Agent |
|---|---|---|
| 任务范围 | 单次推理、片段级生成 | 多步骤规划、项目级实现 |
| 自主性 | 被动响应输入 | 主动拆解任务、调用工具 |
| 反馈机制 | 无自我修正 | 支持“生成→评估→修改”迭代 |
| 典型场景 | 代码补全、注释生成 | 全流程开发、自动调试 |
以百度文心快码为例,其采用了Multi-Agent(多智能体)架构,拆分为Zulu(日常助手)、Plan(策划专家)、Architect(架构师)三个角色。遇到复杂需求时,Architect自动调用子智能体拆解任务,每个子智能体拥有独立上下文,避免了长任务中的“灾难性遗忘”-33。
一句话概括:LLM解决“怎么写”,Agent解决“写什么、写完怎么办” ——前者是能力基础,后者是工程化实现。
四、代码示例:从传统实现到AI文助手
以“实现一个RESTful API的CRUD操作”为例,对比新旧两种实现方式:
传统方式:需要手动编写Controller、Service、Repository层代码,重复编写相似的CRUD模板。
AI文助手方式:
// 在Cursor/通义灵码中输入自然语言注释: // 创建用户实体类User,包含id、name、email字段,并生成对应的Controller, // 实现增删改查接口,使用Spring Data JPA // AI自动生成以下完整代码: @Entity @Table(name = "users") public class User { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String name; private String email; // getters/setters 自动生成 } @RestController @RequestMapping("/api/users") public class UserController { @Autowired private UserRepository userRepository; @GetMapping public List<User> getAllUsers() { return userRepository.findAll(); } @PostMapping public User createUser(@RequestBody User user) { return userRepository.save(user); } // ... 其他CRUD方法 }
关键步骤标注:
AI解析自然语言注释,理解需求意图
检索当前项目上下文(Spring Boot版本、依赖配置)
生成符合项目规范的实体类和Controller
自动补全getter/setter和必要的注解
发生了什么:AI文助手在毫秒级完成了“需求理解→代码检索→模板匹配→代码生成”的全链路过程,开发者只需审查和微调。
五、底层原理与技术支撑
AI文助手的核心能力依赖于以下关键技术栈:
1. 上下文检索与索引:Cursor等工具会建立整个项目的向量索引——将代码库转换为可的“智能地图”,相似的概念进行聚类存储。提问时采用两阶段检索:先向量候选代码片段,再用AI模型按相关性排序-12。
2. 推理与行动模式(ReAct) :AI助手通过ReAct(Reasoning + Acting)模式将LLM转化为多步编码智能体——AI先推理问题、规划步骤,再选择工具执行操作,形成“推理→行动→观察”的循环-12。
3. 规划与反思机制:单智能体通过“先规划,后实现”范式分解复杂任务,集成编译器、静态分析器等外部工具,并通过“生成→评估→修改”的迭代机制持续优化代码质量-11。
这些底层技术构成了从“代码补全”到“自主编码”的能力跃迁,是理解AI文助手工作原理的关键所在。
六、高频面试题与参考答案
Q1:用过哪些AI编程工具?说说使用感受。
参考答案:使用过Cursor和通义灵码。目前整体感觉是AI编程能力进步非常快,已不再是简单的代码补全工具,而是一个可以深度协作的工程助手-54。我的方法论是:在接手复杂项目时先让AI分析代码库生成架构文档,确保人机对项目有一致理解后再编码,显著提升了产出质量-54。
Q2:你如何看待AI对后端开发的影响?AI会淘汰初级程序员吗?
参考答案:AI不会淘汰程序员,而是会淘汰不会使用AI的程序员。AI大幅降低了重复性编码的工作量,让开发者更聚焦于架构设计、业务理解和复杂问题解决-54。但AI生成代码的准确率问题依然存在——2025年仅33%的开发者信任AI准确性,66%反映“几乎正确但不完全正确”的代码是最大困扰-58。理解代码原理、具备审查和优化能力仍是程序员的核心竞争力。
Q3:Cursor等工具的底层是如何实现代码理解的?
参考答案:核心是向量索引+两阶段检索。工具会扫描整个代码仓库构建索引,将代码片段转换为向量存入数据库。用户提问时,先进行向量相似度召回候选代码,再调用LLM对候选结果进行重排序,最终将最相关的上下文输入给模型生成答案-12。通过RAG(检索增强生成)技术,可以从私有代码库中检索相关信息,扩展模型的能力边界-11。
Q4:AI编程助手面临的主要挑战是什么?
参考答案:三大挑战:①准确性问题——Stack Overflow调查显示仅29%的开发者信任AI生成内容的准确性-61;②幻觉问题——AI可能生成语法正确但逻辑错误的代码;③安全与合规风险——AI生成的代码可能引入漏洞或泄露敏感信息。应对策略包括:引入SPEC模式(规范驱动开发)实现“白盒化”代码生成,以及私有化部署确保代码安全-33。
Q5:LLM和Agent的区别是什么?
参考答案:LLM是“大脑”,具备理解和生成能力;Agent是拥有这个大脑的“完整程序员”,额外具备规划、工具调用、自我迭代能力。LLM解决“怎么写”,Agent解决“写什么、写完怎么办”——前者是被动响应,后者是主动闭环-11。
七、结尾总结
本文从传统开发的痛点出发,依次拆解了:
✅ 大语言模型(LLM) :AI文助手的“大脑”,负责理解和生成
✅ 智能体(Agent) :具备自主规划与执行能力的完整系统
✅ 核心差异:LLM是被动工具,Agent是主动协作者
✅ 底层原理:向量索引检索 + ReAct推理行动模式 + 规划反思机制
✅ 面试要点:5道高频题及其标准答案
核心金句:AI文助手不会取代你,但会用AI文助手的开发者会取代不会用的你。理解其原理、善用其能力,同时保持对代码质量的独立判断力,才是AI时代开发者的正确打开方式。
预告:下一篇将深入讲解Agent的Multi-Agent协作架构,拆解多个智能体如何像团队一样分工完成复杂任务,敬请期待。
附录:核心术语对照表
| 英文术语 | 中文术语 | 简要说明 |
|---|---|---|
| LLM (Large Language Model) | 大语言模型 | AI文助手的“大脑”,负责理解与生成 |
| Agent | 智能体 | 具备规划、行动、迭代能力的自主系统 |
| Multi-Agent | 多智能体 | 多个Agent协同完成复杂任务 |
| RAG (Retrieval-Augmented Generation) | 检索增强生成 | 从知识库检索信息辅助生成 |
| ReAct (Reasoning + Acting) | 推理+行动模式 | Agent思考与执行的循环机制 |
| Transformer | 变换器模型 | 现代LLM的核心架构 |
本文基于截至2026年4月的技术进展整理,相关数据与产品信息请以官方最新发布为准。
相关文章
最新评论